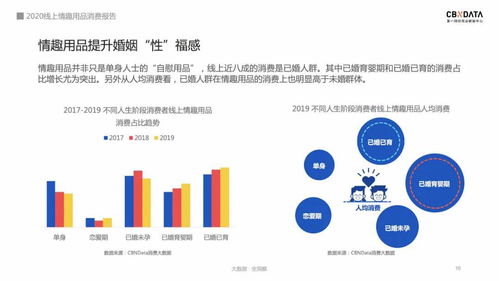
隨著社交媒體平臺的迅速發(fā)展,微博等平臺已成為信息傳播的重要渠道。海量的微博數(shù)據(jù)也帶來了信息管理、內(nèi)容監(jiān)控和安全分析等方面的挑戰(zhàn)。本文旨在探討基于爬蟲技術的網(wǎng)絡空間微博信息管理系統(tǒng)的設計與實現(xiàn),結合網(wǎng)絡與信息安全軟件開發(fā)的理論與實踐,提供一個完整的計算機畢業(yè)設計解決方案。
一、系統(tǒng)需求分析
微博信息管理系統(tǒng)的主要目標是從微博平臺采集數(shù)據(jù),進行高效存儲、分析和可視化,同時確保信息安全。系統(tǒng)需求包括:
- 數(shù)據(jù)采集模塊:利用網(wǎng)絡爬蟲技術,自動化抓取微博內(nèi)容,包括用戶信息、博文、評論和轉發(fā)數(shù)據(jù)。
- 數(shù)據(jù)存儲模塊:設計數(shù)據(jù)庫結構,支持大規(guī)模數(shù)據(jù)的存儲和快速檢索,采用關系型數(shù)據(jù)庫(如MySQL)和NoSQL數(shù)據(jù)庫(如MongoDB)相結合的方式。
- 信息管理模塊:實現(xiàn)數(shù)據(jù)清洗、去重、分類和情感分析功能,幫助用戶監(jiān)控輿情和識別潛在風險。
- 安全與權限管理:集成網(wǎng)絡安全機制,如數(shù)據(jù)加密、訪問控制和防爬蟲反制策略,確保系統(tǒng)運行的合法性和數(shù)據(jù)隱私。
- 可視化界面:提供用戶友好的Web界面,展示數(shù)據(jù)統(tǒng)計結果和實時監(jiān)控信息。
二、系統(tǒng)設計與實現(xiàn)
系統(tǒng)采用分層架構,包括數(shù)據(jù)層、業(yè)務邏輯層和表示層。關鍵技術點如下:
- 爬蟲模塊實現(xiàn):使用Python的Scrapy或Requests庫構建多線程爬蟲,模擬用戶行為以繞過平臺限制。通過API接口或HTML解析獲取數(shù)據(jù),并設置合理的爬取頻率以避免IP封禁。
- 數(shù)據(jù)處理與存儲:對采集的原始數(shù)據(jù)進行預處理,包括去除噪聲、格式統(tǒng)一和關鍵詞提取。數(shù)據(jù)庫設計采用ER模型,確保數(shù)據(jù)一致性和可擴展性。
- 信息安全機制:在數(shù)據(jù)采集和傳輸過程中應用HTTPS協(xié)議,對敏感信息進行加密存儲。引入用戶認證和角色權限系統(tǒng),防止未授權訪問。
- 開發(fā)工具與環(huán)境:使用Java或Python作為后端開發(fā)語言,結合Spring Boot或Django框架;前端采用HTML/CSS/JavaScript和Vue.js;部署在云服務器上,實現(xiàn)高可用性。
三、應用與展望
該系統(tǒng)可廣泛應用于政府輿情監(jiān)控、企業(yè)品牌管理和學術研究中。可集成機器學習算法以提升情感分析和異常檢測的準確性,并擴展至多平臺數(shù)據(jù)采集,以增強系統(tǒng)的通用性。通過本設計,開發(fā)者可以掌握網(wǎng)絡爬蟲、數(shù)據(jù)庫管理和信息安全等核心技能,為網(wǎng)絡與信息安全領域貢獻實用工具。
基于爬蟲的微博信息管理系統(tǒng)不僅能夠高效處理海量數(shù)據(jù),還能在網(wǎng)絡安全框架下提供可靠的信息管理方案。本畢業(yè)設計源碼85633為相關開發(fā)提供了參考,強調了在數(shù)據(jù)驅動的時代中,平衡效率與安全的重要性。